
In the ever-evolving landscape of high-performance computing, Nvidia has once again taken a monumental leap forward with its revolutionary strategies in GPU virtualization scheduling. As computational demands continue to escalate in both scientific research and enterprise applications, the efficiency and flexibility of GPU resource allocation have become critical factors in ensuring optimal performance. Nvidia’s innovative approach to GPU virtualization not only addresses these challenges but also offers unprecedented scalability and resource management capabilities. By leveraging advanced algorithms and cutting-edge technologies, Nvidia is setting new standards for how virtualized environments can harness the full power of GPUs, enabling seamless workload balancing, reduced latency, and enhanced throughput.
Development of GPU virtualization Stratagy
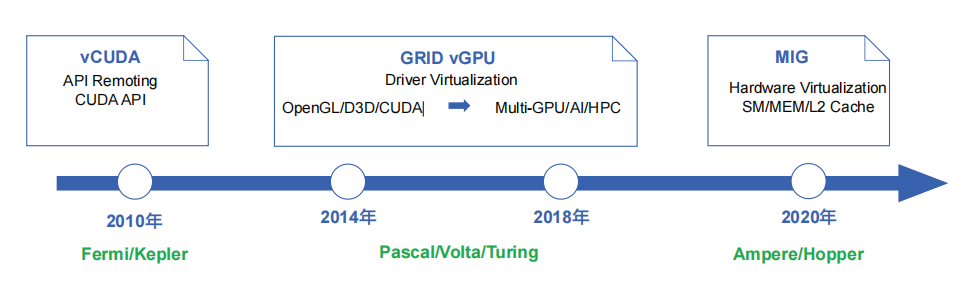
Image Source: NVIDIA
The development path of GPU virtualization is divided into three stages: the API Remoting stage represented by vCUDA, the Driver Virtualization stage represented by GRID vGPU, and the Hardware Virtualization stage represented by MIG.
The first stage, known as the API Remoting stage, is epitomized by solutions like vCUDA. During this phase, virtualization was achieved through the remoting of GPU APIs, allowing applications to leverage GPU resources from remote servers, albeit with certain limitations in performance and compatibility.
The second stage, the Driver Virtualization stage, saw a substantial leap forward with the introduction of NVIDIA GRID vGPU. This innovation enabled multiple virtual machines to share a single physical GPU, significantly enhancing resource utilization and providing more consistent and reliable performance across different virtual environments. GRID vGPU technology facilitated the seamless delivery of rich graphical experiences in virtual desktops and applications, revolutionizing industries such as VDI (Virtual Desktop Infrastructure) and remote work.
The third and most recent stage, Hardware Virtualization, is represented by NVIDIA’s Multi-Instance GPU (MIG). MIG technology allows a single physical GPU to be partitioned into multiple independent instances, each with its own dedicated resources. This represents a pinnacle in GPU virtualization, offering unparalleled performance isolation, scalability, and resource efficiency. MIG is particularly transformative for data centers and cloud computing, as it enables precise allocation of GPU resources to diverse workloads, from AI training to inferencing and beyond.
These stages highlight NVIDIA’s relentless pursuit of innovation in GPU virtualization, pushing the boundaries of what is possible and setting new industry standards in computational performance and efficiency.
(Read “GPU Positioning for Virtualized Compute and Graphics Workloads” for additional information.)
 Image Source: Pexels
Image Source: Pexels
API Remoting and vCUDA
vCUDA technology appeared around 2010. Its implementation idea is to provide a logical image of a physical GPU in the virtual machine – a virtual GPU, intercept the CUDA API in the user mode, and redirect the virtual GPU to the real physical GPU to perform calculations. . At the same time, based on the native CUDA runtime library and GPU driver, the vCUDA server is run on the host, taking over the CUDA API intercepted by the virtual GPU, and scheduling computing tasks.
How vCUDA works
The CUDA runtime library of the virtual machine is replaced with vCUDA, whose function is to intercept all CUDA API calls from the CUDA App. The vCUDA runtime library calls the vGPU driver (or “client driver”) in the kernel. The actual function of the vGPU driver is to send CUDA calls through the VMRPC (Virtual Machine Remote Procedure Call) channel from the virtual machine to the host. to the host machine. After receiving the CUDA call, the host’s vCUDA Stub (management side) calls the real CUDA runtime library and physical GPU driver on the host to complete the GPU operation.
Before the client driver processes the API, it needs to apply for GPU resources from the management side. Each independent calling process must apply for GPU resources from the host’s management side to achieve real-time scheduling of GPU resources and tasks.
Obviously, vCUDA is a time slice scheduling virtualization technology, which is “time division multiplexing”. This kind of implementation is transparent to user applications and does not require any modifications to the virtual GPU. It can also achieve very flexible scheduling, and the number of virtual machines that a single GPU can serve is not limited. But the shortcomings are also obvious: CUDA API is only one of the APIs used in GPU computing. There are other API standards in the industry such as DirectX/OpenGL, and the same set of APIs has multiple different versions (such as DirectX 9 and DirectX 11, etc.) , compatibility is very complex.
How does Nvidia solve this problem in the next generation of GPU virtualization technology?

GRID vGPU
Nvidia launched a replacement for vCUDA – GRID vGPU around 2014. GRID vGPU is a GPU sharding virtualization solution that can also be considered a paravirtualization solution. “Fragmentation” actually uses “time division multiplexing”.
How GRID vGPU works
The CUDA application in the VM calls the native CUDA runtime library, but the GPU driver in GuestOS (virtual machine operating system) does not access the physical BAR (BaseAddress Register) of the GPU, but accesses the virtual BAR.
When performing calculations, the GPU driver of GuestOS will pass the GPA that saves the workload to be calculated to the GPU driver in HostOS through MMIO CSR (Configuration and Status Register), so that the GPU driver of HostOS can obtain the GPA and convert it into HPA. , written to the MMIOCSR of the physical GPU, that is, starting the computing task of the physical GPU.
After the physical GPU completes the calculation, it will send an MSI interrupt to the HostOS driver. The HostOS driver will check and submit the vGPU instance of this Workload based on the Workload, and send the interrupt to the corresponding VM. The VM’s GuestOS handles the interrupt until the workload calculation is completed, reported to CUDA and the application, and the vGPU calculation process is completed.
The vGPU solution is also called the MPT (Mediated Pass Through, controlled pass-through) solution. The idea of this solution is to virtualize some sensitive resources and key resources (such as PCI-E configuration space and MMIO CSR), while the MMIO of the GPU memory is passed through, and a virtualization-aware driver is added to HostOS. To schedule hardware resources. In this way, a PCI-E device can be seen in the VM and the native GPU driver can be installed.
The advantage of this solution is that it inherits the scheduling flexibility of vCUDA and does not need to replace the original CUDA API library, solving the compatibility problem of the previous generation of vCUDA. The flaw of this solution is that the driver on the host is controlled by the hardware manufacturer, and the physical GPU driver is the core of the entire scheduling capability. In other words, this solution is dependent on the manufacturer’s software, and the manufacturer’s software can charge high software licensing fees based on this.

Nvidia MIG
Driven by the industry, Nvidia updated its generation of GPU virtualization solution MIG (Multi-Instance GPU) around 2020. NVIDIA’s Multi-Instance GPU (MIG) technology represents a significant advancement in GPU virtualization. MIG allows a single NVIDIA AI GPU to be partitioned into up to seven independent instances, each with its own dedicated memory, cache, and compute resources. This capability ensures that multiple workloads can run concurrently without interfering with each other, providing performance isolation and improved resource utilization.
How Nvidia MIG works
The similarity between MIG and vGPU is that the CUDA runtime library and GPU driver on the VM are native versions. But the difference is that the GPU device seen on MIG is actually part of the real physical hardware, and its BAR and MMIO CSR are both real physical hardware behind it.
This is a hardware capability introduced by Nvidia on high-end GPUs such as Nvidia A100 and Nvidia H100. It can not only virtualize 7 instances of a GPU chip for use by different VMs, but also allocate designated GPU computing to the virtualized instances. Power and GPU memory, this is actually a kind of spatial division multiplexing, that is, hardware resource isolation (Hardware Partition).
An important value brought by hardware resource isolation is hardware fault isolation. In the first two solutions, essentially, no real fault isolation is achieved on the GPU side. Once a CUDA job submitted to Nvidia accesses the GPU memory out of bounds, CUDA applications in other VMs may throw errors. was aborted with an exception. MIG provides a hardware security mechanism so that programs in different MIG instances will not affect each other, thus solving this problem from the root.
This is the current state of the art development focused on accelerating artificial intelligence and deep learning tasks via GPUs. NVIDIA’s Tensor Core GPUs like the V100, A100, and the latest H100 are the product of this phase. These GPUs are specially optimized for AI and deep learning. They have powerful computing power and efficient memory bandwidth, and support various precision calculations (such as FP32, FP16, INT8, etc.), greatly improving the training and inference performance of AI models.
NVIDIA H100 Tensor Core GPU, based on the new Hopper architecture, represents the current highest level of GPU technology and focuses on accelerating AI, deep learning and high-performance computing tasks, further promoting the third phase of development.
Conclusion
Nvidia’s groundbreaking strategies in GPU virtualization scheduling are setting new benchmarks in the industry. From the pioneering API Remoting stage to the advanced Multi-Instance GPU (MIG) technology, Nvidia has continually pushed the envelope, offering unparalleled efficiency, scalability, and performance isolation. These innovations are not only transforming how resources are managed in data centers and virtual environments but are also paving the way for future advancements in artificial intelligence, data analysis, and high-performance computing.
For enterprises looking to leverage these cutting-edge technologies, partnering with a reliable provider is crucial. Router-switch.com stands out as a seasoned expert in the field with 22 years of industry experience. Renowned for their competitive pricing, robust after-sales support, and guaranteed product quality, offering comprehensive technical support to ensure you get the most out of your Nvidia GPUs. Whether you’re looking to enhance your existing infrastructure or embark on new computational ventures, Router-switch.com has the expertise and solutions to meet your needs.

Expertise Builds Trust
20+ Years • 200+ Countries • 21500+ Customers/Projects
CCIE · JNCIE · NSE7 · ACDX · HPE Master ASE · Dell Server/AI Expert
